
Insight
Why Most Internal Knowledge Chatbots Fail with Confluence and Teams


[ Executive Overview ]
Most enterprise internal knowledge chatbots fail because of weak RAG infrastructure—not the LLM itself. Fragmented data across Confluence, Teams, and internal wikis makes real-time synchronization, retrieval, and semantic search difficult. Wissly solves this through enterprise-grade RAG architecture built for continuous data syncing and secure knowledge retrieval.
Why Traditional Enterprise Search Fails at Scale
In the modern enterprise, intellectual assets are rarely centralized. Product specifications live in Confluence, daily operational alignments happen across Microsoft Teams or internal wikis, and standard operating procedures (SOPs) float around as local internal documents.
When data scales, traditional keyword-matching search engines quickly hit a wall due to two systemic issues:
The Semantic Gap: If an employee searches for "Remote Work Policy" but the official documentation is titled "Telecommuting Guidelines," legacy systems fail to bridge the semantic connection.
Data Refresh Delay: When teams update a project scope or modify a wiki page, traditional search engines fail to re-index the changes immediately, leading the AI to serve outdated, obsolete data.
To eliminate these gaps, Wissly introduces a high-performance Internal RAG Search infrastructure driven by automated, real-time data pipelines.
How Does Wissly’s Enterprise RAG Architecture Work?
Wissly eliminates the friction of manual, one-off file uploads. By establishing direct API connections with your legacy systems and collaboration hubs, it creates an end-to-end knowledge assetization engine.
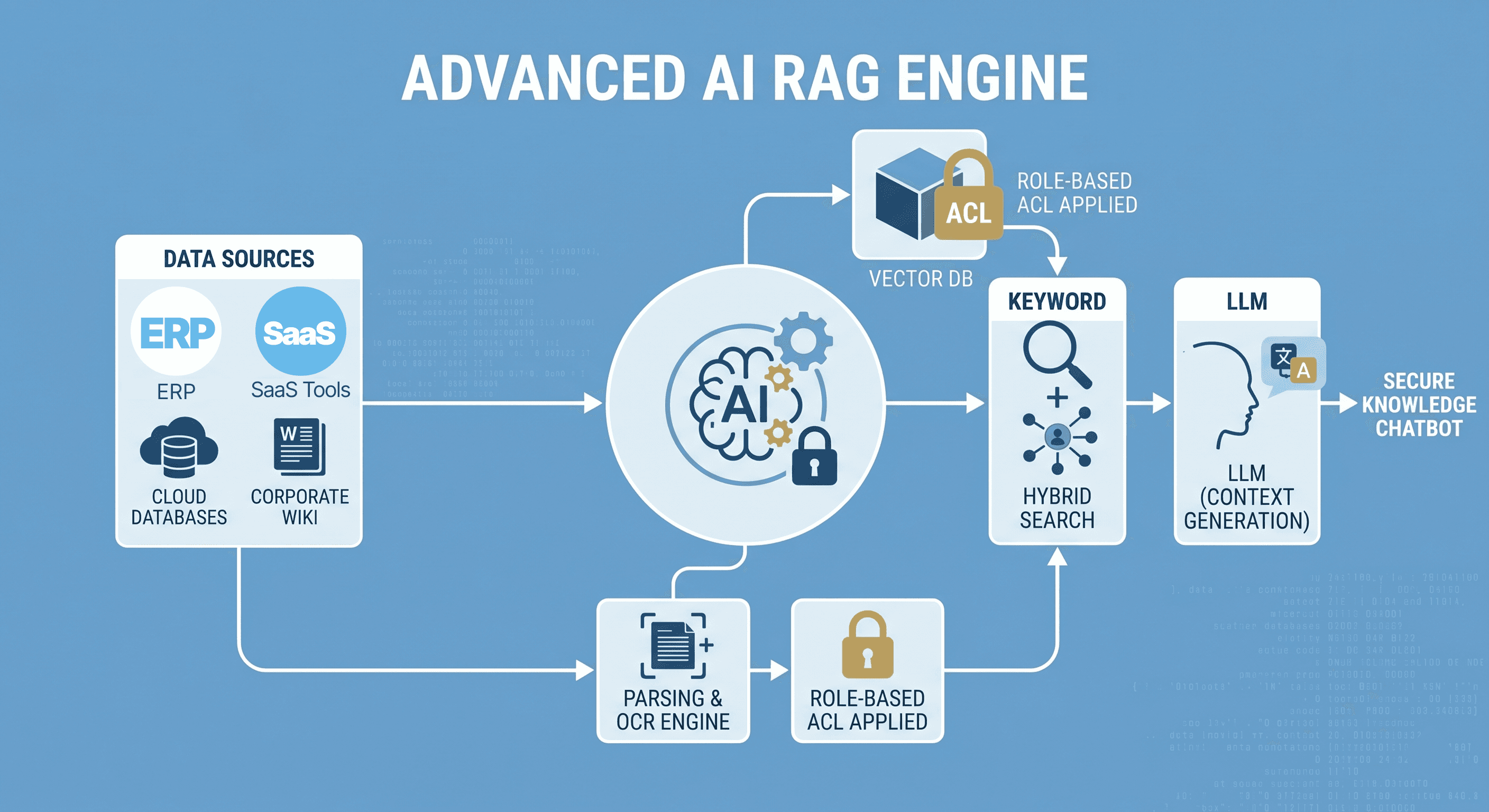
2-1. Real-Time Sync via Hybrid Connectors
Operating as a dedicated Confluence Document Chatbot and Teams Document RAG Bot, Wissly deploys optimized webhook listeners and scheduler-based connectors. Instead of heavy, full-scale database re-indexing, Wissly tracks Delta Data (incremental updates) within your wikis and Teams channels, minimizing infrastructure overhead while keeping data perfectly fresh.
2-2. Advanced Document Parsing & Data Cleansing
Up to 80% of RAG performance is determined before the data even hits the LLM—during the data cleansing and chunking phase. Wissly features a proprietary parsing engine that extracts complex table structures from Excel sheets and specialized local formats (like HWPX), restructuring them into clean Markdown. Scanned physical documents are instantly digitized via an integrated high-fidelity OCR layer.
2-3. Semantic Chunking & Hybrid Retrieval
Splitting text arbitrarily by character count destroys context. Wissly utilizes Semantic Chunking to break down documents based on logical context and layout boundaries before generating high-density vector embeddings.
During a query, Wissly executes a Hybrid Search strategy—combining keyword-based Sparse Retrieval with meaning-based Dense Retrieval—and runs a Reciprocal Rank Fusion (RRF) re-ranking algorithm to guarantee absolute source precision.
Infrastructure Matrix: Open-Source RAG vs. Wissly Enterprise
Technical Vector | Standard Open-Source RAG | Wissly Enterprise Infrastructure |
Data Synchronization | Manual, file-by-file uploads | Native, real-time Confluence & Teams API Sync |
Format Adaptability | Limited to plain text, PDFs, and TXT | Advanced parsing for 14+ formats (DOCS,PDF,ODF, XLSX, PPTX) |
Chunking Strategy | Fixed-size chunking (frequent context loss) | Semantic & Layout-aware intelligent chunking |
Retrieval Engine | Single-vector embedding search | Hybrid Search + Reciprocal Rank Fusion (RRF) |
Data Scalability | Limited to small-scale token thresholds | Production-ready for 5,000+ documents / 10,000+ pages |
How Do Enterprise RAG Systems Handle Access Control?
An Internal Knowledge Chatbot is a liability if it bypasses corporate governance. If the system cannot respect user permissions, it cannot be deployed.
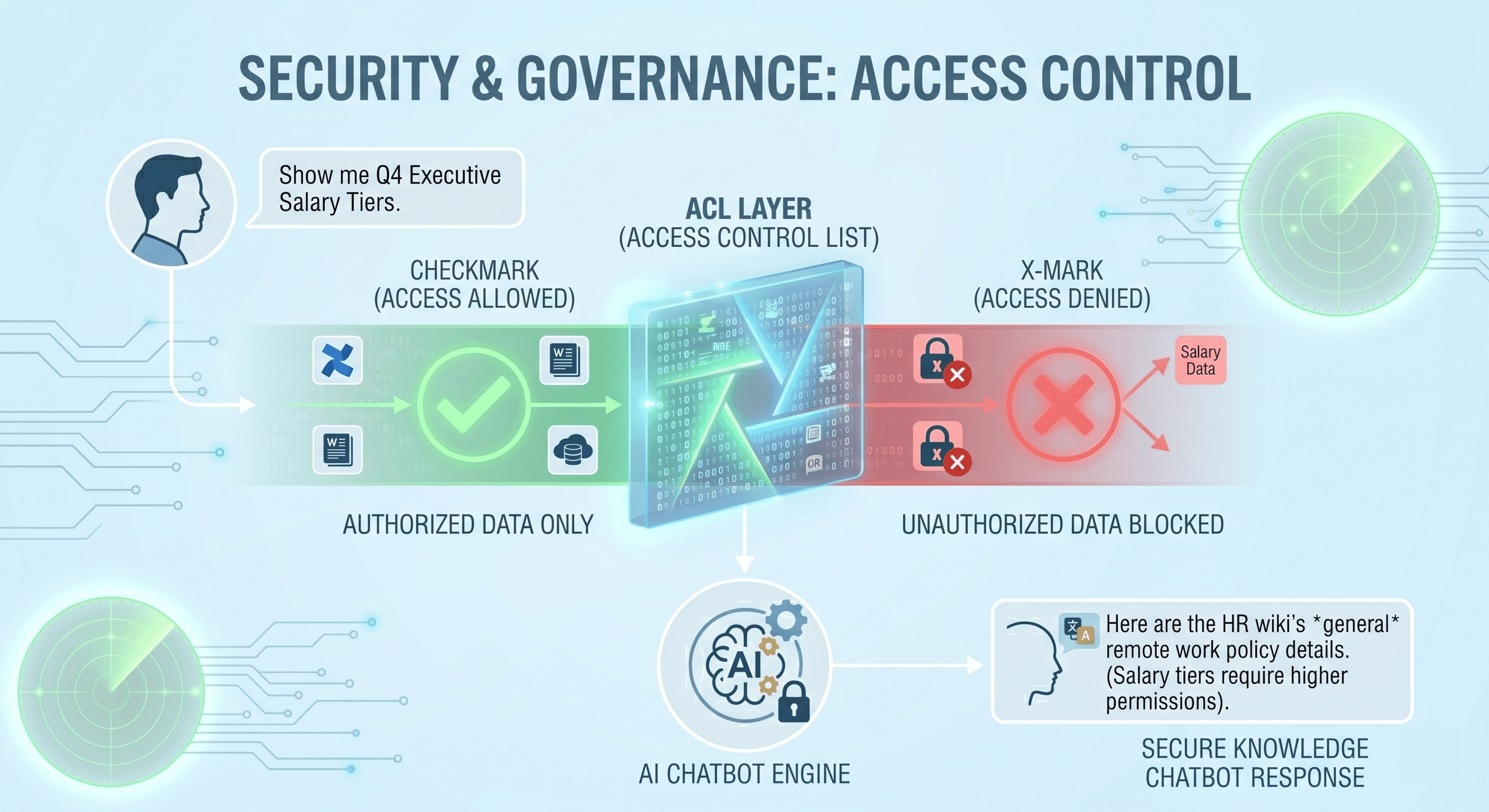
Wissly integrates a strict security validation layer directly into the RAG pipeline. It inherits the existing permission profiles from Confluence and Teams. If a general staff member asks, "Show me the executive salary tier from the HR wiki," the RAG engine filters out unauthorized data at the vector retrieval level. This ensures absolute data security while driving seamless employee task automation.
Conclusion: Robust Infrastructure Powers True Intelligence
The real capability of an AI solution lies beneath the chatbot interface. True workplace transformation requires a robust RAG pipeline backed by real-time integration with your day-to-day collaboration tools. By unifying data ingestion, advanced parsing, and live system syncing into a single architecture, Wissly transforms fragmented enterprise knowledge into a secure, continuously synchronized AI retrieval layer.
Common Questions About Enterprise RAG and Internal Knowledge Chatbots
Q1. Why do most internal knowledge chatbots fail?
A1. Most failures come from weak RAG infrastructure, not the LLM itself. Enterprise knowledge is fragmented across Confluence, Teams, wikis, and local files, making real-time retrieval difficult.
Q2. How does a Confluence chatbot stay synchronized in real time?
A2. Enterprise RAG systems use webhook listeners and incremental sync pipelines to detect document changes instantly without full re-indexing.
Q3. Why is traditional enterprise search ineffective?
A3. Keyword-based search cannot understand semantic meaning. Searches like “remote work policy” may fail if the document is titled differently.
[Enterprise Infrastructure AX Proposal]
⚙️ Robust Architecture. Reliable Intelligence.
📂 [Request an Enterprise PoC] Connect Wissly's connectors to your active Confluence, Teams, or internal wiki environment for a live technical evaluation.
💬 [Schedule an Infrastructure Audit] Consult with a Wissly systems engineer regarding secure on-premise deployment architectures and air-gapped network RAG configurations.
🧪 [Try the Live RAG Demo] Experience real-time Confluence and Teams retrieval with Wissly’s enterprise AI infrastructure.
Recommended Content






