
인사이트
AI 어시스턴트 비교: ChatGPT vs Danswer vs 위슬리, 왜 문서 분석 성능이 갈리는가


"단순한 답변을 넘어 지식을 해독하다"
지난 [Part 1. 신뢰의 기술] 환각(Hallucination) 방지와 RAG의 본질에서 우리는 전문가 그룹에게 왜 정확한 근거 제시가 필수적인지 살펴보았습니다.
하지만 실제 현장에서 마주하는 문서는 그리 호락호락하지 않습니다. 수만 장에 달하는 대용량 매뉴얼과 수치 데이터가 빽빽한 복합 표(Complex Table)는 일반적인 RAG 솔루션들이 무너지는 지점입니다. 오늘은 글로벌 솔루션들과의 비교를 통해, 위슬리(Wissly)가 어떻게 이 '해독의 난제'를 해결했는지 기술적으로 분석합니다.
주요 RAG 솔루션별 장단점 및 기술 분석
비교 항목 | ChatGPT Enterprise | Danswer (오픈소스) | 위슬리 (Wissly) |
대용량 문서 처리 | 토큰 제한으로 인한 성능 저하 | 인덱싱 속도 및 검색 정밀도 기복 | 수십만 장 규모의 고성능 인덱싱 |
복합 표 분석력 | 낮음 (데이터 손실 및 수치 왜곡) | 기본 파서 의존 (병합 셀 인식 불가) | 좌표 기반 Table Parsing 엔진 |
보안 환경 | 퍼블릭 클라우드 전용 | 자체 구축(보안 책임 본인) | SaaS / VPC / 온프레미스(선택) |
운영 리소스 | 낮음 (SaaS) | 매우 높음 (전문 엔지니어 필수) | 낮음 (매니지드 자동 업데이트) |
🔍 솔루션별 실무적 장단점 평가
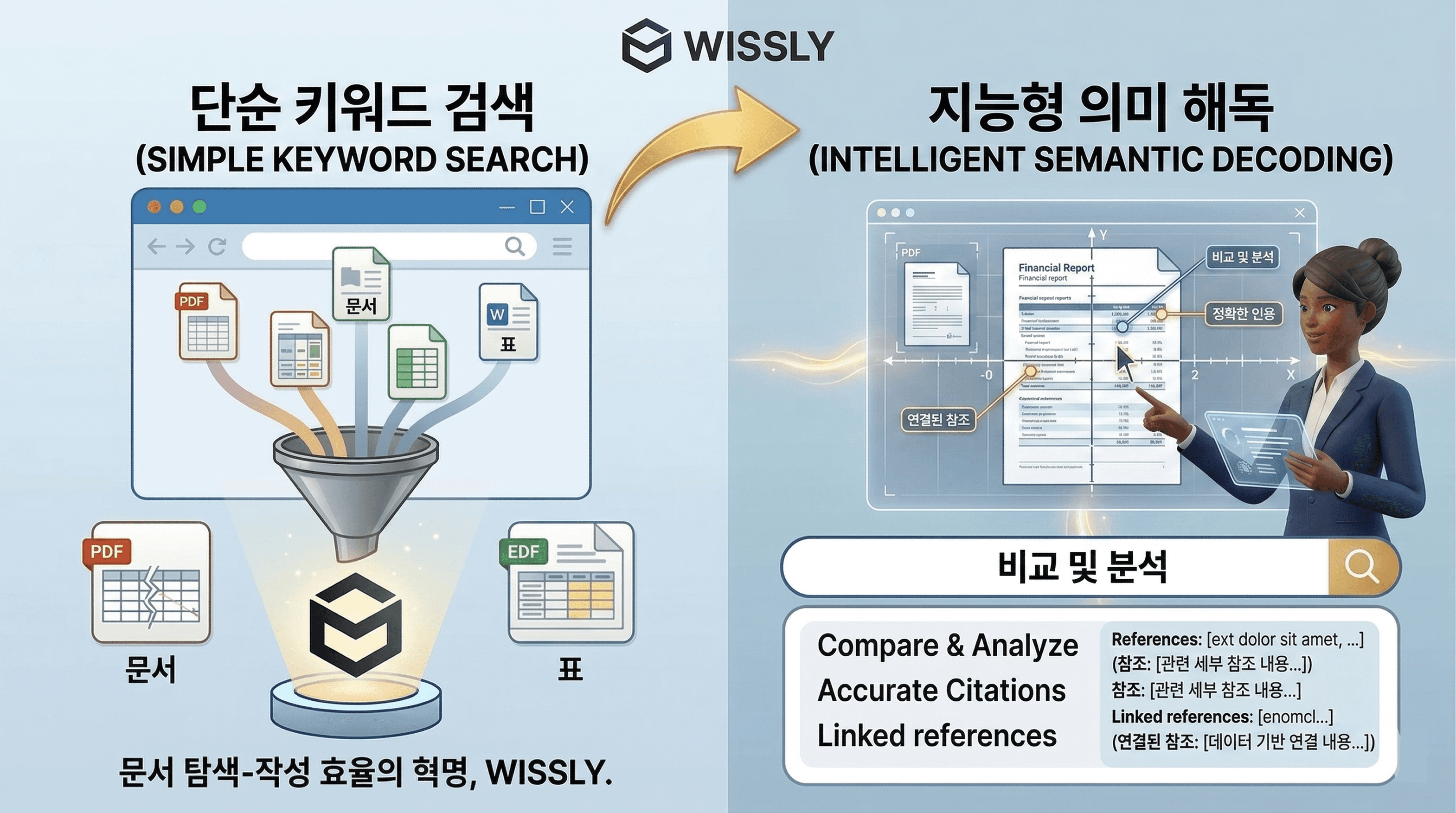
ChatGPT Enterprise: 문장 생성력이 매우 뛰어나 범용 비서로는 훌륭하지만, 보안상 폐쇄망 구축이 불가능하며 표 데이터 인식 시 수치를 왜곡하는 환각 현상이 잦습니다.
Danswer (Open Source): 도입 비용이 없으나 한국어 전문 용어 처리가 미흡합니다. 특히 성능을 유지하기 위해 고가의 개발 인력이 상주해야 하므로 실질 운영비(TCO)가 높습니다.
위슬리 (Wissly): 수십만 장의 대용량 문서에서도 속도 저하가 없으며, 금융·법률의 핵심인 표 데이터 해독력이 독보적입니다. 고객사 환경에 맞춰 클라우드부터 완전 폐쇄망까지 선택 가능한 유연성을 갖췄습니다.
위슬리(Wissly)가 증명하는 '하이엔드'의 조건
3-1. 무제한에 가까운 Scale: "수만 권의 매뉴얼도 단일 지능으로"
일반적인 RAG는 문서량이 늘어날수록 검색 정밀도가 급격히 떨어집니다. 위슬리는 분산 벡터 인덱싱 기술을 통해 수십만 장의 대용량 문서에서도 단 1초 만에 필요한 정보를 식별합니다. 이는 파편화된 조직의 지식을 하나의 '지능형 OS'로 통합할 수 있는 유일한 방법입니다.
3-2. 표(Table) 해독의 정점: "좌표 단위의 구조적 파싱"
금융 보고서의 5단 병합 표나 법률 약관 대조표는 단순 텍스트가 아닙니다. 위슬리는 표의 레이아웃을 좌표 단위로 해독하여 행과 열의 관계를 완벽히 보존합니다. 수치를 글자로만 읽어 엉뚱한 답변을 내놓는 일반 AI와 달리, 위슬리는 구조를 이해하여 오답 리스크를 원천 차단합니다.
FAQ: 실무자를 위한 RAG 선택 가이드
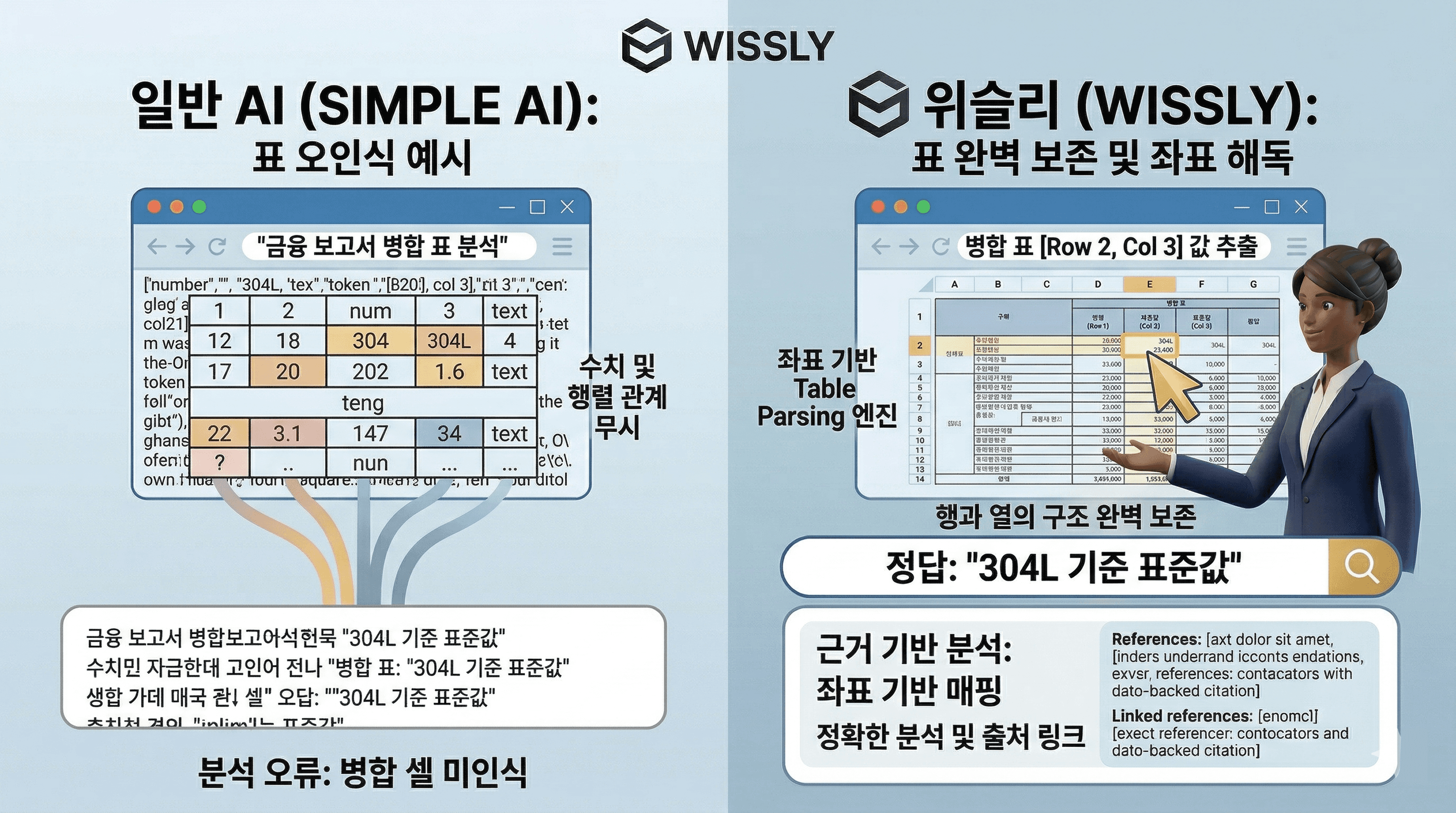
Q1: 대용량 문서(10만 페이지 이상) 환경에서 RAG 검색의 정밀도를 유지하는 방법은 무엇인가요?
A1: 일반적인 RAG는 데이터 볼륨이 커질수록 노이즈가 증가하여 검색 정확도가 하락합니다. 위슬리(Wissly)는 이를 해결하기 위해 분산 벡터 인덱싱(Distributed Vector Indexing)과 하이브리드 시맨틱 검색(Hybrid Semantic Search)을 결합합니다. 백만 페이지 단위의 대규모 아카이브에서도 질문의 의도를 다각도로 분석하여 1초 이내에 최적의 근거를 추출하며, 문서량에 관계없이 일관된 고정밀 응답 성능을 보장합니다.
Q2: Danswer 등 오픈소스 RAG 대비 위슬리의 유지보수 및 운영 효율성은 어느 정도인가요?
A2: 오픈소스 RAG는 검색 최적화와 한국어 임베딩 튜닝을 위해 전담 엔지니어의 지속적인 개입이 필수적입니다. 반면, 위슬리는 노코드 매니지드 아키텍처(No-code Managed Architecture)를 채택하여 전문 기술 인력 없이도 운영이 가능합니다. 직관적인 어드민 대시보드를 통해 실무자가 직접 지식 베이스를 업데이트하고 관리할 수 있어, 기존 구축형 대비 운영 리소스를 80% 이상 절감하는 효과가 있습니다.
Q3: ChatGPT Enterprise와 비교했을 때, 위슬리의 복합 표(Complex Table) 분석 기술은 어떤 차별점이 있나요?
A3: 범용 LLM은 PDF 내의 표를 단순 텍스트로 인식하여 행과 열이 뒤섞이는 환각 현상이 발생하기 쉽습니다. 위슬리는 표의 레이아웃을 좌표 단위로 인식하는 Table Parsing 기술을 통해 병합된 셀이나 다중 헤더가 포함된 복합 표의 구조를 완벽하게 보존합니다. 수치 데이터의 무결성이 중요한 금융·법률 업무에서 오답 리스크를 원천 차단하는 것이 위슬리만의 독보적인 차별점입니다.
결론: "비교를 넘어 확신으로"
다양한 툴을 검증해 본 전문가들이 결국 위슬리에 정착하는 이유는 명확합니다. 대용량 데이터를 처리하는 규모(Scale)와 표 데이터를 해독하는 정교함(Precision)을 동시에 만족하는 솔루션은 드물기 때문입니다. 기술적 해자가 분명한 위슬리로 리스크 없는 AX를 시작하십시오.

[Next Preview]
Part 3. [전환의 기술] 사내 지식 자산화와 도입 ROI (단순 유틸리티를 넘어선 지능형 OS로)
우리 조직에 최적화된 RAG 성능 확인하기
📂 [무료 시작하기] [위슬리의 정밀한 데이터 학습 직접 확인하기]
🚀 [성능 비교 PoC] [ChatGPT vs 위슬리, 우리 회사 데이터로 직접 성능 테스트 신청]
추천 콘텐츠






