
Tech
Why AI Misses Key Information in Long Documents ― The “Lost in the Middle” Problem and How Wissly Addressed It
Dec 30, 2025


Does Giving AI More Context Always Lead to Better Answers?
When teams apply AI to internal document search or Q&A, a common assumption quickly emerges:
“If we give the model more relevant information, won’t it produce more accurate answers?”
In practice, this intuition often breaks down.
As documents get longer—or as more content is passed to the model at once—answer quality can actually degrade.
This counterintuitive behavior has been consistently observed in both research and real-world systems, and it is closely tied to a phenomenon known as “Lost in the Middle.”
What Is the “Lost in the Middle” Problem?
Modern large language models (LLMs) can technically process tens or even hundreds of thousands of tokens in a single prompt.
However, being able to accept long context is not the same as effectively using it.
Multiple studies show a consistent pattern as context length increases:
Information at the beginning of a document is used well
Information at the end of a document is used well
Information in the middle is much more likely to be ignored
This results in a U-shaped performance curve, where accuracy drops most sharply for content located in the middle of the input context.
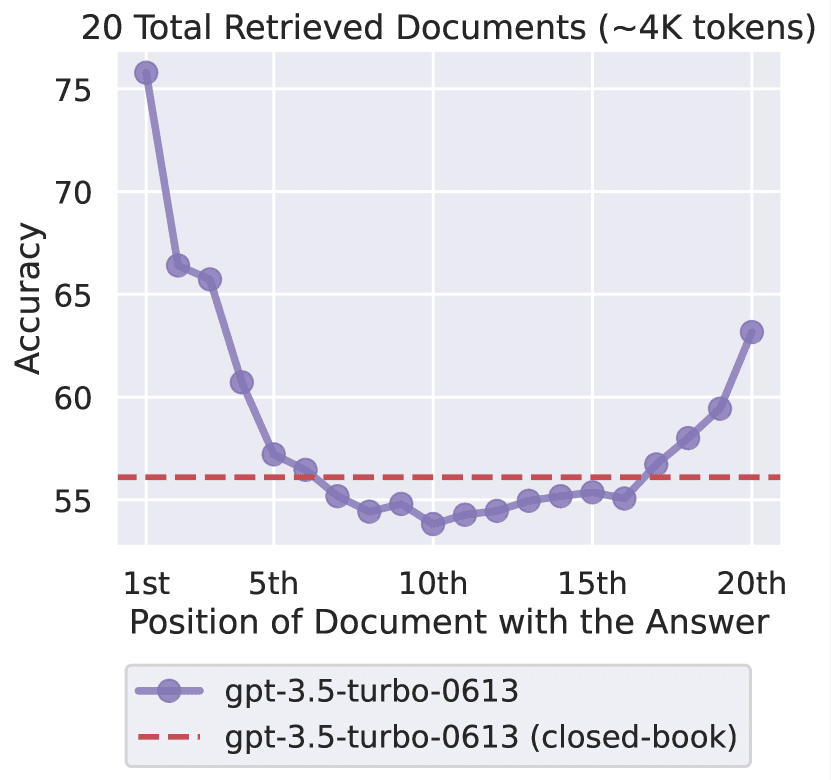
This behavior is commonly referred to as the “Lost in the Middle” problem.
Importantly, this is not simply a limitation of small context windows.
The same pattern appears even in long-context models such as GPT-4 and Claude.
Why Does This Happen?
The root cause lies in how LLMs process long sequences.
LLMs do not read documents linearly the way humans do. Instead, they rely heavily on early and late context to infer:
What kind of question is being asked
What type of answer is expected
As a result, information placed in the middle of a long context is less likely to be treated as a strong signal and is more easily deprioritized.
This behavior reflects a structural limitation of Transformer-based attention mechanisms, where token position still plays a significant role in how information is weighted.
Why This Is Especially Problematic for Document-Based RAG
The issue becomes far more severe in document-based RAG (Retrieval-Augmented Generation) systems.
Enterprise documents tend to be:
Long and structurally complex
Rich in details that appear deep within the body, not just in summaries
Retrieved in batches, with multiple chunks passed to the model at once
In practice, this leads to a frustrating pattern:
More documents are retrieved
Key chunks end up buried in the middle
Answer accuracy drops
Token usage and cost increase
The result is an ironic failure mode:
even with “enough context,” the model still produces incorrect or incomplete answers.
Limitations of Existing Approaches
A range of context-engineering techniques have been proposed to mitigate this issue:
Context reordering: placing important passages at the beginning or end of the prompt
Selective retrieval: using only the top-ranked results instead of all retrieved chunks
Prompt compression: removing redundancy and summarizing low-importance content
While these approaches help, none fully solve the problem on their own.
In practice, most systems rely on incremental improvements rather than a single definitive fix.
Wissly’s Approach
Reducing and Reconstructing Retrieved Context
One pattern consistently emerged during Wissly’s internal analysis:
Retrieval accuracy was not the bottleneck.
Problem: “More Retrieval” Can Be Counterproductive
In early versions of Wissly’s RAG pipeline, the top 20–30 retrieved chunks were passed directly to the model.
This created two major issues:
Less relevant chunks diluted the model’s attention
Answer-critical chunks were often pushed into the middle of the context and ignored
High recall at retrieval time was unintentionally creating low-precision prompts.
Strategy 1: Recall at Retrieval, Precision at Generation
Wissly deliberately separated the roles of each stage:
Retrieval stage: maximize recall—don’t miss relevant content
LLM input stage: maximize precision—only include what truly matters
The revised pipeline follows this flow:
Retrieve a broader set of candidates
Apply a secondary filtering and compression step
Pass no more than five core chunks to the LLM
This ensures the model receives a context it can realistically process with focus.
Strategy 2: Relevance Is Not the Same as Similarity
Vector search ranks chunks by semantic similarity—but similarity alone does not guarantee answer usefulness.
Through experimentation, Wissly found that:
The most similar chunk is not always the most decisive one.
Final ordering therefore incorporates additional signals:
Direct relevance to the question’s intent
Presence of conclusions, definitions, or numerical values
Redundancy across retrieved chunks
This approach is conceptually similar to LangChain’s LongContextReorder, but customized for Wissly’s document structures and query patterns.
Strategy 3: Place the Most Important Chunk Last
A key rule emerged:
The chunk most likely to contain the answer should appear at the end of the prompt.
This intentionally leverages the model’s recency bias, observed in “Lost in the Middle” research.
Because LLMs rely heavily on the most recently processed information during generation, placing the decisive chunk last significantly increases the likelihood that it is reflected in the final answer.
Results
After applying these changes, Wissly observed clear improvements in both accuracy and user satisfaction.
Internal evaluation showed:
Overall answer accuracy improved by approximately 15 percentage points
Questions whose answers appeared in the middle of documents saw especially strong gains
User feedback confirmed these findings:
Average answer satisfaction increased from 4.1 / 5 to 4.5 / 5
Users reported that responses now included details that were previously hard to surface
Performance improvements extended beyond quality:
Average retrieval time decreased by over 20%
Reduced context size lowered token usage and API costs
Even with the same models (Gemini 3.0, Claude 4.5 Sonnet), answers became more stable and complete
Closing Thoughts
The “Lost in the Middle” problem has not been fully eliminated.
Very long documents and complex multi-step reasoning can still expose limitations.
However, Wissly’s experience shows that this issue is not something teams must simply accept.
With thoughtful RAG design—especially around context selection, ordering, and compression—the impact can be significantly reduced.
Wissly will continue incorporating the latest research in long-context modeling and retrieval optimization to further improve reliability in document-based AI systems.
Recommended Content






