
인사이트
한국어 OCR 병목을 줄인 방법


EasyOCR에서 PP-OCRv5로 전환하고, 필요한 부분만 재학습으로 보완한 사례
문서 자동화는 대개 “추출 → 구조화 → 검증 → 업무 시스템 반영”으로 이어집니다.
그런데 이 흐름에서 가장 앞단에 있는 OCR이 흔들리면, 뒤 단계가 아무리 좋아도 자동화 전체가 기대한 수준으로 작동하기 어렵습니다.
스텝하우 개발팀이 처음 겪었던 문제도 비슷했습니다.
텍스트가 ‘조금’ 틀리는 정도가 아니라, 업무에 치명적인 방식으로 틀렸고, 처리 시간이 길어지면서 처리 흐름이 자주 막히는 상황이 반복되었습니다.
이번 글에서는 그 병목을 PP-OCRv5 기반 스택으로 전환하고, 남는 예외 케이스를 최소 범위 재학습으로 메우며 문서 처리 품질을 끌어올린 과정을 소개합니다.
(아래 수치와 결과는 공개 벤치마크가 아니라, 스텝하우 내부 문서/환경에서의 측정값입니다.)
자동화가 느려지고, 검수가 늘어나는 순간
한국어 OCR에서 문제는 보통 두 갈래로 나타납니다.
첫째는 신뢰도입니다.
1,500,000원이 1,500,00O원으로 읽히거나, 010-7104-8028이 0l0-7l04-8028로 바뀌는 순간(0/O, 1/I/l 혼동), 추출 결과는 그대로 쓰기 어렵습니다.

금액, 계좌번호, 전화번호, 문서번호, URL처럼 중요한 필드는 한 글자만 틀려도 실패로 이어지기 때문에, 결국 사람이 다시 확인해야 합니다. 자동화가 “되어 있지만 사람 손이 필요한 구조”로 남는 이유입니다.
둘째는 처리 속도입니다.
처리 시간이 길어질수록 문서 처리 흐름은 자연스럽게 보수적으로 변합니다. 중간 점검이 늘고, 오류가 나면 재실행이 반복되고, 결과적으로 문서가 쌓이면서 업무가 밀리기 시작합니다.
스텝하우 개발팀은 이 두 문제가 동시에 발생하면서, 문서 자동화의 병목이 OCR에 있다는 것을 분명히 확인했습니다.
접근 방식: “좋다더라”보다 “같은 조건에서 직접 비교”
특정 OCR이 좋다는 평가는 많지만, 실제로 중요한 건 스텝하우가 실제로 처리하는 문서에서 어떤 실패를 내는지입니다.
스텝하우 개발팀은 전처리/페이지 분할/병렬 처리 방식/후처리 규칙을 고정한 뒤, 엔진만 바꿔가며 내부 비교를 진행했습니다.
목표는 단순했습니다.
한글/숫자/영문 혼동이 의미 있게 줄어드는가
배치 처리에서 처리 시간이 줄어드는가
(가능하다면) GPU 없이도 안정적으로 동작하는가
예외 케이스가 생겼을 때, 보완할 방법이 있는가
이 관점에서 선택한 방향이 PP-OCRv5 기반 스택이었습니다.
전환 결과: 처리 시간과 오인식 패턴 개선 (내부 측정)
PP-OCRv5로 전환한 뒤 가장 크게 달라진 건, 단순히 “더 빨라졌다”가 아니라 문서 처리 과정에서 사람이 개입해야 하는 지점이 줄었다는 것이었습니다.
처리 시간이 짧아지면 문서가 대기열에 쌓이지 않습니다.
그만큼 결과 확인이 빨라지고, 오류가 났을 때도 바로 재처리할 수 있어 전체 흐름이 끊기지 않습니다.
또 한글/숫자/영문을 헷갈려서 생기던 오인식이 줄면서,
금액·전화번호·문서번호처럼 한 글자만 틀려도 문제가 되는 필드를 사람이 다시 확인하는 일이 눈에 띄게 줄었습니다.
스텝하우 내부 측정 기준으로는 다음과 같은 변화가 있었습니다.
처리 시간: PDF 100장 기준 50분 → 10분 수준
오인식 감소: 핵심 필드(금액/전화번호/문서번호/URL)에서 혼동 패턴이 크게 줄어 검수 부담 감소
메모리 사용량 감소: 같은 서버에서 더 많은 문서를 동시에 처리해도 안정적으로 동작
정리하면, 이번 전환의 효과는 “정확도 수치가 올랐다”보다 결과를 믿고 다음 단계로 바로 넘길 수 있는 문서가 많아졌다는 점에 있습니다.
그런데, 모델 교체만으로 끝나지 않는 문제: 배경색이 들어간 표 셀
대부분의 문제는 해결되는 듯했지만, 한 가지가 남았습니다.
연한 배경색이 들어간 표 셀에서 특정 텍스트가 아예 누락되는 케이스였습니다.
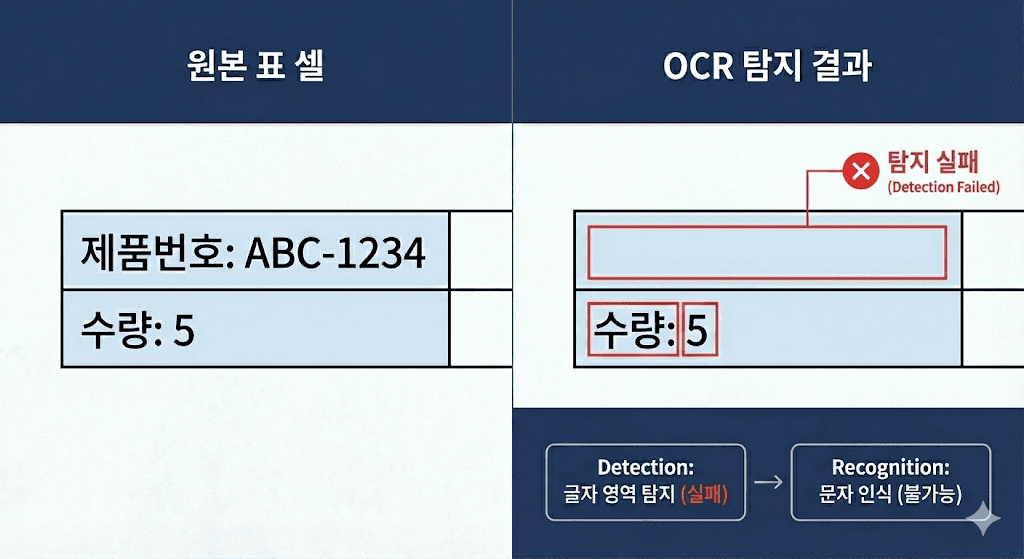
이 문제는 단순 오인식이 아니라, 글자 영역을 찾지 못하는 현상이었습니다.
OCR은 크게 두 단계로 동작합니다.
Detection: 글자가 어디 있는지 찾는 단계
Recognition: 찾은 영역을 실제 문자로 읽는 단계
이번 케이스는 Recognition이 아니라 Detection 단계에서 텍스트 영역이 누락된 것이었습니다.
배경색이 들어가면 글자와 배경의 대비가 낮아지는데, 이때 모델이 해당 부분을 “글자 영역”으로 확신하지 못하면 아예 영역 자체를 잡지 않고 넘어갑니다.
영역을 못 잡으면, 그 다음 단계에서 아무리 잘 읽는 모델이어도 결과에는 누락으로 나타날 수밖에 없습니다.
그래서 밝기 조절, 대비 강화, 흑백 변환 같은 전처리를 해도 일부 케이스는 끝까지 남았습니다.
해결: 필요한 패턴만 모아서 최소 범위로 재학습
스텝하우 개발팀은 접근을 바꿨습니다.
전체를 다시 학습하는 대신, 반복적으로 실패하는 패턴을 모아 필요한 범위만 재학습했습니다.
방식은 단순합니다.
누락되는 패턴을 데이터로 정의하고
그 패턴을 대표하는 샘플을 충분히 모은 뒤
모델이 해당 영역을 “텍스트 영역”으로 인식하도록 학습한다
이 과정은 생각보다 큰 규모의 데이터가 필요하지 않았습니다.
“무엇이든 읽는 범용성”보다, 반복되는 실패를 제거하는 것이 더 중요했기 때문입니다.
재학습 이후에는 배경색 표 셀에서의 누락이 크게 줄었고, 표 기반 문서의 처리 안정성이 확실히 좋아졌습니다.
정리: OCR은 ‘텍스트 추출’이 아니라 ‘신뢰도를 만드는 과정’이다
이번 개선을 통해 스텝하우 개발팀이 얻은 결론은 단순합니다.
OCR은 “글자를 읽는 기능”이 아니라, 문서 자동화 전체의 신뢰도를 결정하는 출발점이라는 점입니다.
OCR을 “돌려서 나온 결과를 그대로 쓰는 단계”로 두면, 결국 사람 검수는 항상 남습니다.
반대로 OCR을 “문서 자동화의 품질을 설계하는 단계”로 두면 접근이 달라집니다.
스텝하우 개발팀은 PP-OCRv5 기반 전환으로 기본 성능을 끌어올리고,
끝까지 남는 예외는 최소 범위 재학습으로 보완하면서 “검수해야 하는 문서”를 줄였습니다.
문서 자동화에서 병목은 종종 가장 앞단에 숨어 있습니다.
이번 경험은 그 병목을 푸는 일이 단순히 “더 좋은 OCR을 고르는 것”이 아니라,
반복되는 실패를 어떻게 관리하고 줄일지까지 포함한 설계 문제라는 점을 분명히 보여줬습니다.
추천 콘텐츠






